





Claude Mythos Coding and AI Dev Workflows
- News
- Claude Code
Claude Mythos matters less as a headline benchmark win than as a workflow signal. Based on the public record, Anthropic is treating Mythos Preview as a model class that is strong enough in coding, autonomy, and security work to require a gated rollout through Project Glasswing rather than a normal public launch. That is the real story for development teams: once a model can understand large codebases, find serious flaws, and help turn them into exploits, the question stops being “Is this the best coding model?” and becomes “How do we govern where this capability is allowed to operate?”
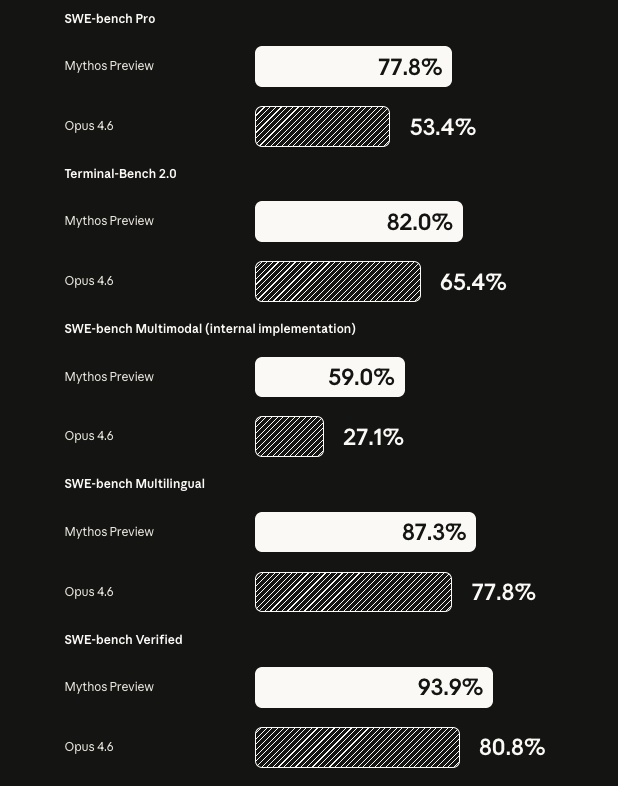
Anthropic’s own numbers make the jump hard to dismiss. On its Project Glasswing announcement page, Mythos Preview is shown outperforming Opus 4.6 on SWE-bench Pro, Terminal-Bench 2.0, SWE-bench Multilingual, and SWE-bench Verified, including 93.9% on SWE-bench Verified versus 80.8% for Opus 4.6. At the same time, Anthropic explicitly notes important evaluation caveats, including memoriztion screening and the fact that Terminal-Bench outcomes depend on harness settings, token budgets, and resource allocation.
That combination is why Mythos is so significant. It is not just a stronger coding assistant. It is an early sign that top-end code agents are becoming powerful enough that access control, review paths, and security policy will matter as much as prompt quality or model ranking.
Quick verdict
- Mythos is best understood as a governance event, not just a benchmark event.
- Most teams do not need Mythos access today, but they do need to start designing workflows for Mythos-class agents.
- The teams that should move first are platform, security, and large-repo engineering teams, not ordinary feature teams. This is an interpretation based on the public rollout pattern and the kinds of tasks Anthropic says the initiative will focus on.
What the benchmark lead actually says
The public benchmark table matters because it shows that Mythos is not being presented as a narrow cyber tool. Anthropic describes the model as its most capable yet for coding and agentic tasks, and the Glasswing page ties the cyber story directly to broader gains in code understanding, modification, and reasoning. That means the right reading is not “Anthropic trained a security model.” The stronger reading is that frontier coding ability has advanced to the point where security consequences have become impossible to separate from software engineering capability.
That distinction matters for AI dev workflows. If a model becomes meaningfully better at long-horizon coding, repository navigation, test iteration, and multi-step problem solving, then the same model is also likely to become better at vulnerability reproduction, exploit construction, and patch generation. Anthropic says exactly that in its red-team write-up: the exploit capability emerged downstream from improvements in code, reasoning, and autonomy rather than from explicit training for offensive security.
Why this changes workflows more than leaderboards
The most important public evidence is not the leaderboard. It is the red-team result set. Anthropic’s researchers describe Mythos as capable of finding and exploiting serious vulnerabilities across major operating systems and browsers, including a Firefox experiment where Opus 4.6 produced working exploits only twice in several hundred attempts while Mythos produced working exploits 181 times and reached register control 29 additional times. They also report that Mythos achieved 595 tier-1 and tier-2 crashes in OSS-Fuzz testing and reached ten fully patched tier-5 targets, which indicates full control-flow hijack.
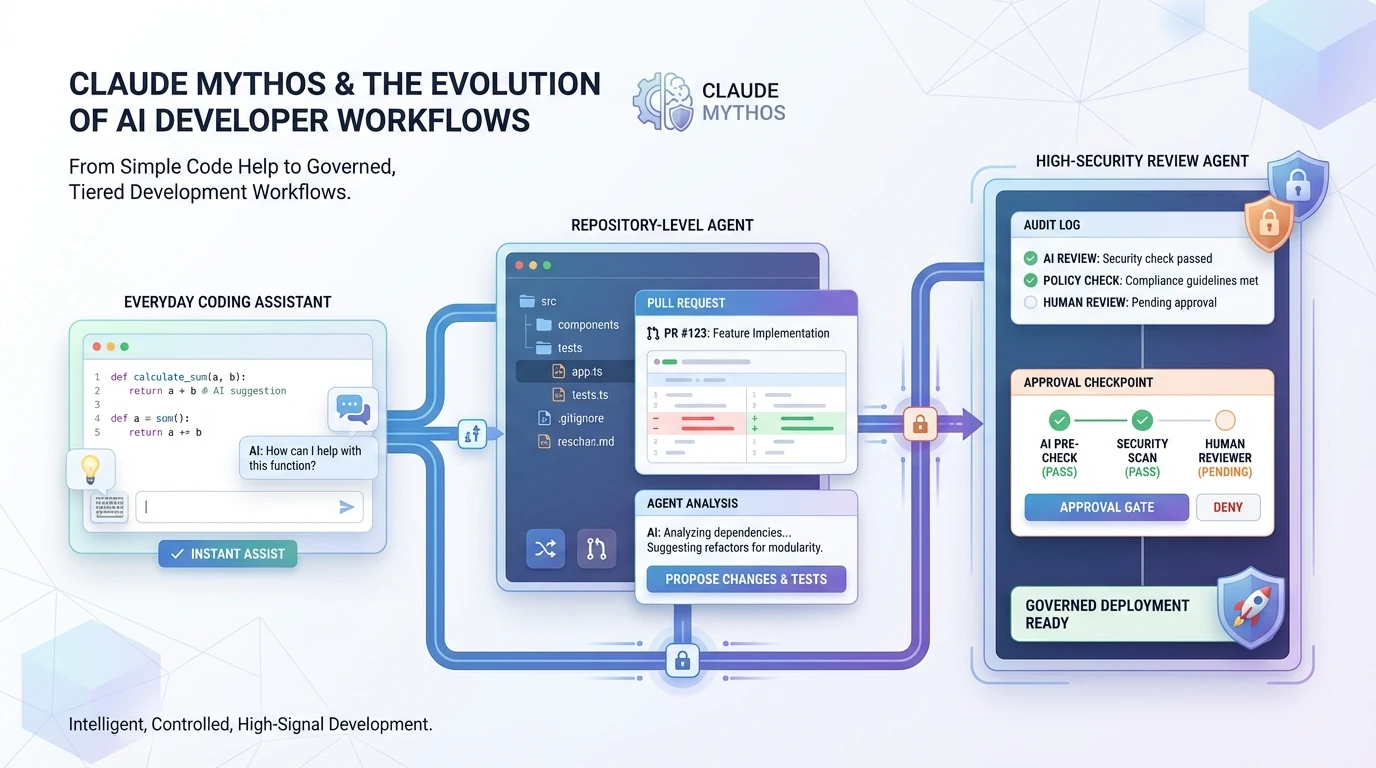
That should change how teams think about AI coding tools. A conventional coding assistant mainly accelerates local tasks: boilerplate, refactors, documentation, test writing, and isolated debugging. A Mythos-class agent points to something else: repo-scale triage, multi-file patching, exploit-aware review, and deeper automation around security-sensitive engineering work. Once the model can operate across that wider surface area, the workflow problem becomes organizational. Who is allowed to run it, against which code, with which tools, under whose review, and with what audit trail? The public record does not prescribe a universal answer, but it strongly suggests that those questions are now first-order engineering questions rather than edge-case security questions.
The limited rollout reinforces that conclusion. Anthropic says Project Glasswing includes 12 launch partners, extends access to more than 40 additional organizations that build or maintain critical infrastructure, and is backed by up to $100 million in usage credits. AWS separately says Bedrock access is a gated research preview in US East (N. Virginia) and limited to an initial allow-list. This is not the release pattern of a normal developer productivity model. It is the release pattern of a capability that needs staged deployment and operational controls.
How teams should redesign model roles
The practical takeaway is not that every team should wait for Mythos. Anthropic’s own red-team post says defenders without access should still use generally available frontier models now, because current models remain highly capable at finding vulnerabilities even if they are much less effective at creating exploits. It also says that building the right scaffolds and procedures with current models is useful preparation for when Mythos-class capability becomes more widely available.
For most organizations, that points to a three-tier model strategy.
Tier 1: everyday coding assistants
This tier covers IDE help, lightweight refactors, internal docs, and routine debugging. The priority here is speed, availability, and low operational friction rather than maximum autonomous power. Teams do not need a Mythos-class model for this layer.
Tier 2: repository and CI agents
This is where the next real workflow upgrade will happen. These agents need to reason across modules, run tests, propose patches, explain regressions, and summarize risk. The right question is not whether they beat a benchmark leaderboard. It is whether they are reliable enough to sit inside a controlled review loop with strong logging and predictable permissions. Anthropic’s own focus areas for Project Glasswing include local vulnerability detection, black-box testing of binaries, triage scaling, and patching automation, which maps closely to this middle layer.
Tier 3: security-specialist agents
This layer should stay tightly controlled. Once a model can discover and validate severe vulnerabilities, demonstrate exploitability, or operate over high-value internal code at large scale, the organization needs different controls from those used for ordinary coding copilots. The public rollout of Mythos strongly suggests that the future stack will separate high-capability security agents from general-purpose developer assistants.
The more practical conclusion is that teams should upgrade process before they chase frontier access. Logging, sandboxing, approval gates, least-privilege tool access, and human escalation paths are not optional details anymore. They are part of the product surface of advanced code agents.
Why benchmark winners do not automatically become production defaults
Anthropic’s own engineering write-up on agentic coding evals is the clearest reason to avoid simplistic benchmark conclusions. The company says infrastructure configuration alone can swing agentic coding benchmarks by several percentage points, and in its internal experiments the gap between the most- and least-resourced Terminal-Bench 2.0 setups was 6 percentage points. That is a large enough difference to distort many “model A beat model B” narratives.
This does not make Mythos’ lead unimportant. It makes the interpretation more precise. Static benchmarks mostly measure model output. Agentic coding benchmarks also measure the surrounding runtime: time limits, tool access, compute ceilings, and execution reliability. So the operational question for teams is not “Which model won?” but “Which model-plus-runtime setup solves the right class of engineering work under the controls we can actually enforce?”
That is why production evaluation should prioritize five things over leaderboard obsession: reliability, controllability, auditability, permission boundaries, and useful output per unit cost. Anthropic itself lists Mythos Preview pricing for participants at $25 per million input tokens and $125 per million output tokens, which is another reminder that the best model on paper is not automatically the best default production choice.
Who should move now and who can wait
The teams that should move now are the ones already close to high-consequence code or high-autonomy tooling. That includes security teams, platform teams building internal coding agents, large software vendors with complex repositories, and organizations in infrastructure-heavy or regulated environments. Project Glasswing itself is centered on critical software, open-source maintainers, and large technology and security organizations, which is a strong signal about where near-term value is expected to land first.
The teams that can wait are ordinary product teams whose main AI use cases are still local code generation, refactoring help, and documentation acceleration. For them, the biggest win in 2026 is unlikely to be direct Mythos access. It is more likely to be adopting stronger review loops, better scaffolds, and clearer separation between low-risk copilots and higher-risk autonomous agents. That is an interpretation, but it follows directly from Anthropic’s recommendation to start building procedures with current frontier models rather than waiting for Mythos itself.
The bigger signal for 2026
The bigger signal is that restricted release is becoming part of the product story for top-end coding models. Anthropic says it does not plan to make Mythos Preview generally available and instead wants to develop safeguards that can later support safer deployment of Mythos-class models at scale. That framing matters because it suggests the frontier is moving toward layered availability rather than one-size-fits-all access.
For AI development teams, the strategic implication is straightforward. The next generation of workflow advantage will not come from prompt tricks. It will come from model tiering, runtime design, tool permissions, review orchestration, and security-aware automation. Mythos matters because it makes that future legible a little earlier than many teams expected.
FAQ
Is Claude Mythos publicly available to ordinary developers?
No. Anthropic says it does not plan to make Mythos Preview generally available, and current access is being managed through Project Glasswing and other gated research-preview channels. AWS also says Bedrock availability is limited to an initial allow-list of organizations.
Why is Mythos more important than a normal benchmark jump?
Because the public evidence ties its coding gains to autonomy and security impact, not just coding convenience. Anthropic presents Mythos as its strongest model for coding and agentic tasks, and its red-team results show meaningful exploit-development capability rather than a small productivity bump.
Does this mean public coding models are no longer useful?
No. Anthropic explicitly says current frontier models remain useful for vulnerability discovery and that teams should start building scaffolds and procedures with them now. The gap is not between “useful” and “useless.” It is between ordinary coding assistance and high-autonomy, high-consequence agent behavior.
What should engineering leaders do first?
Start by separating model roles before chasing frontier access. The safest first move is to define which tasks belong to low-risk copilots, which belong to review-bound repo agents, and which should be reserved for security-specialist workflows with stricter controls. This recommendation is an interpretation, but it is the one most consistent with the way Mythos is being rolled out.


_11zon.webp)

Claude Code Leak 2026: Which Hidden Features Are Real?
A verification-first breakdown of the Claude Code leak, separating public capabilities, plausible roadmap clues, and pure speculation.
By Mila 一 Apr 10, 2026- News
- Claude Code

Will Iran Develop Nuclear Weapons? AI Assesses the Risks and Timeline
Iran’s nuclear ambitions have remained a flashpoint for global security discussions for over two decades. With diplomatic agreements fraying and enrichment capacity expanding,
By Mila 一 Apr 10, 2026- War
- News
- AI Predict

When Will the Russia-Ukraine War End?
The Russia-Ukraine war has become one of the most significant conflicts in modern European history, reshaping alliances and altering the global economic landscape. With years of fighting, sanctions, and international mediation attempts, many around the world are asking: when will the war finally end?
By Mila 一 Apr 10, 2026- War
- News
- AI Predict
- X
- Youtube
- Discord