





Why HappyHorse-1.0 Is #1 on AI Video Leaderboards
- AI Video
- AI Video Generator
- HappyHorse
HappyHorse-1.0 did not become important because of a splashy public launch. It became important because the live Artificial Analysis text-to-video leaderboard and image-to-video leaderboard now place it at or near the top of the most visible human-preference rankings in AI video. As of April 9, 2026, it leads text-to-video without audio at 1386 Elo, text-to-video with audio at 1232 Elo, and image-to-video without audio at 1412 Elo; in image-to-video with audio, it sits effectively tied with Dreamina Seedance 2.0 720p at 1164 Elo.
That is why it feels “sudden.” HappyHorse-1.0 was also added to both Artificial Analysis leaderboards within the last month, which means the ranking shock is not coming from a long, gradual climb. It is coming from a newly listed model immediately outperforming many established closed models in blind user preference tests.
Quick verdict
What the ranking shows: HappyHorse-1.0 is winning on public visual preference right now, especially in no-audio text-to-video and image-to-video.
What the ranking does not show: It does not prove that HappyHorse-1.0 is the easiest model to access, integrate, price, govern, or scale in production. Artificial Analysis still marks its API status as “Coming soon.”
What creators should do: Treat HappyHorse-1.0 as a model worth tracking closely, not as an automatic instruction to rebuild your workflow around it today. This is an evidence-based judgment drawn from the gap between leaderboard strength and rollout clarity.
Why the leaderboard jump matters
The headline is not just that HappyHorse-1.0 is ranked first. The more important detail is how Artificial Analysis calculates that rank. The site says its Elo scores are derived from blind comparisons in the Video Arena, where users compare two videos generated from the same prompt without knowing which model made which output. That matters because it strips out a lot of brand bias and turns the leaderboard into a measure of preference under direct A/B comparison, not vendor messaging.
That also helps explain why HappyHorse-1.0 feels disruptive. When a new model lands on a blind-preference board and immediately beats Seedance, Kling, grok-imagine-video, and others, the strongest interpretation is not “the market found a better press release.” It is that users are repeatedly preferring what this model produces when they are not told whose logo is attached to it.
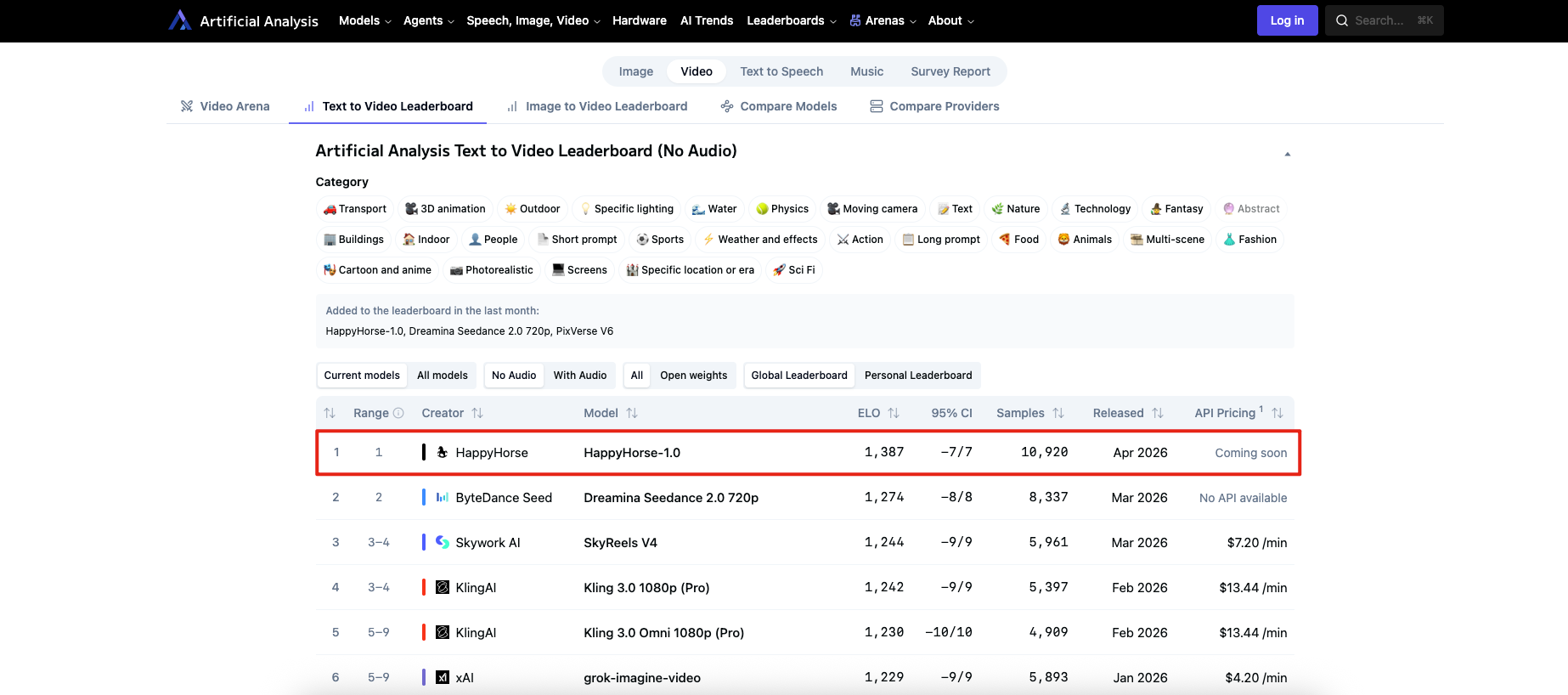
Why HappyHorse-1.0 is likely winning right now
Based on the available evidence, the most practical explanation is that HappyHorse-1.0 is outperforming rivals on the parts of video quality that people notice immediately in blind voting. Its edge is largest in image-to-video without audio, where it leads Dreamina Seedance 2.0 720p by 54 Elo points, and substantial in text-to-video without audio, where it leads by 112 Elo points. Those are not tiny margins. They suggest that the model is consistently producing outputs users find more convincing at first watch.
For creators, image-to-video may be the more revealing signal. Text-to-video rankings tell you how strong a model looks from scratch. Image-to-video rankings often tell you something more operationally useful: how well a model preserves a source image while adding motion. That matters for product creatives, speaking avatars, campaign variations, explainer assets, and any workflow where consistency matters more than prompt novelty. The leaderboard itself does not spell out those use cases, but the inference is supported by where HappyHorse-1.0 is strongest and by how video teams actually use image-to-video systems.
What the board rewards, though, is preference. It is very good at surfacing “which output do people like more.” It is less complete as a measure of controllability, editability, governance, onboarding friction, or deployment readiness. That is not a flaw in the leaderboard. It is just a reminder that “best-looking in blind votes” and “best choice for a content team this month” are related questions, not identical ones.
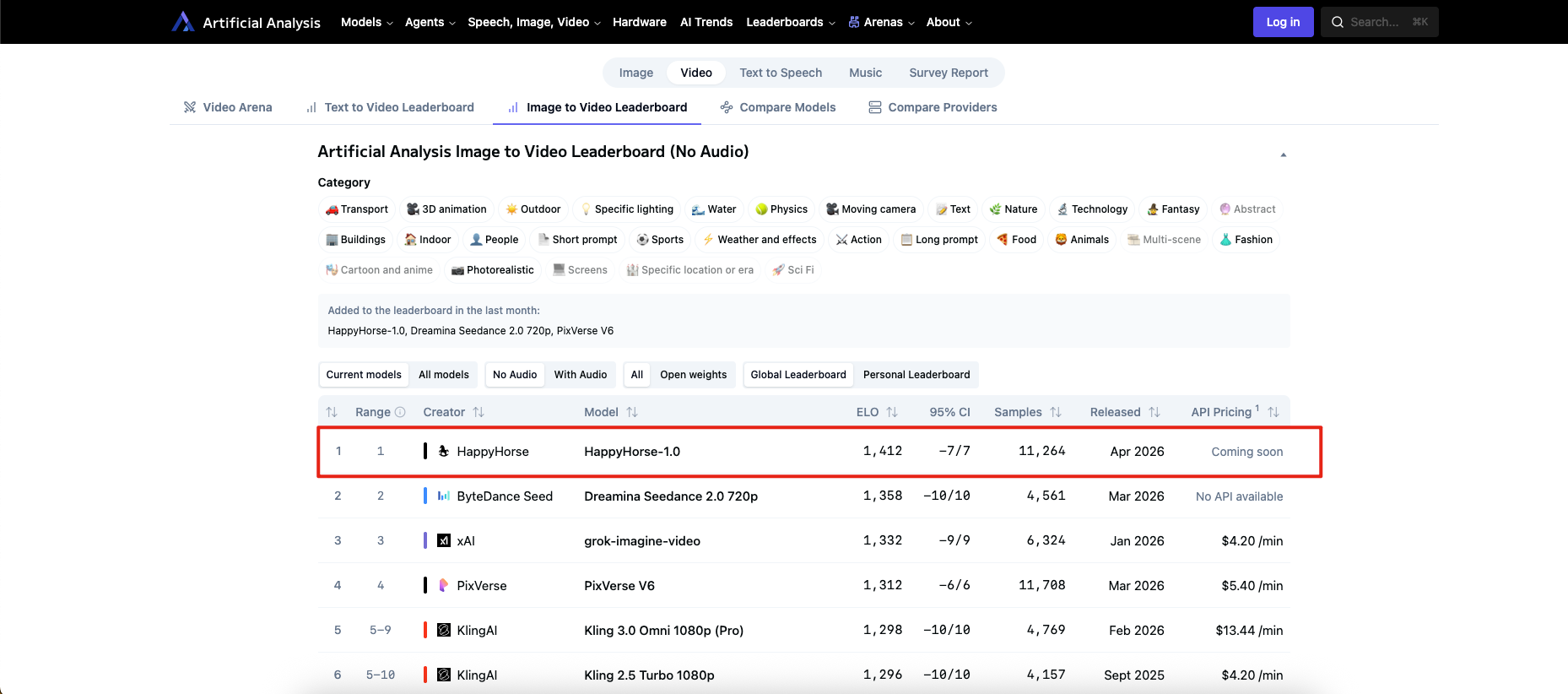
What the ranking proves, and what it does not
The ranking proves that HappyHorse-1.0 is performing extremely well in blind human preference tests on Artificial Analysis right now. It also proves that this is not an old model being rediscovered; the site lists it as a new addition from the last month and dates it to April 2026 on the board.
The ranking does not prove that HappyHorse-1.0 is the best operational choice for every team. Artificial Analysis still shows “Coming soon” for API pricing and availability. In the same FAQ sections, the platform’s open-weights leaders are currently LTX models, not HappyHorse-1.0. So even if HappyHorse is leading the overall preference charts, that is different from being the clearest open, self-hostable, ready-to-integrate option.
That distinction matters because production teams buy more than output quality. They also buy access, documentation, predictable cost, rights clarity, latency, failure handling, and toolchain fit. A leaderboard can tell you who is winning the beauty contest. It cannot, on its own, tell you who will cause the fewest problems in a real pipeline.
The public record on HappyHorse-1.0 is still inconsistent
This is where the story gets more interesting. One public page on Happy Horses says HappyHorse is a video-generation capability inside the HappyHorses platform, “not offered as a standalone model,” and “not provided as a standalone model or independently distributed model service.” The same page also says HappyHorses is an independent AI platform and does not claim ownership of the underlying model technologies.
A different public site, happyhorse-ai.com , presents a different narrative. It says the model “will be fully released as open source,” that GitHub and model hub links are “coming very soon,” and that HappyHorse 1.0 was released by the Future Life Lab of Taotian Group, led by Zhang Di.
Those two narratives do not sit neatly together. One describes a platform capability that is not a standalone model offering. The other describes an openly released model with a named team and imminent source availability. That does not mean either page is necessarily false. It does mean the rollout story is still unsettled in public, and any article that presents the model’s distribution status as fully resolved is moving faster than the evidence supports.
Who should care now, and who should wait
Creators and content teams should care now if their work depends on image-to-video quality, speaking-character consistency, localized content, or repeatable short-form production. The HappyHorses platform page itself positions the capability around multilingual lip-sync, ad creative production, content team output, training videos, and localization. Even if that page is platform-focused rather than model-focused, those are exactly the kinds of workflows where a ranking jump like this can matter.
Teams should wait before restructuring around it if they need a stable API, a clearly documented standalone release, or an unambiguous licensing and distribution path. The current public evidence still points to “strong ranking, unclear rollout.” That is exciting for market watchers and frustrating for operators, which is a common pattern when a model’s preference signal outruns its packaging.
The wider lesson is bigger than HappyHorse-1.0 itself. AI video is entering a phase where visual preference leadership can shift quickly, and where “best model” is becoming a two-part question: who wins the vote, and who shows up ready for work. Right now, HappyHorse-1.0 looks like a leader in the first category. The second category is still taking shape.
FAQ
Is HappyHorse-1.0 actually open source?
Not in a fully verified, settled sense yet. One public site says the model will be fully open sourced soon, with GitHub and model hub links coming, while another public-facing platform says HappyHorse is not offered as a standalone model service.
Why is HappyHorse-1.0 described as “suddenly” #1?
Because it was added to the Artificial Analysis leaderboards within the last month and immediately rose to the top of several key categories. The speed of that move, not just the rank itself, is what makes the story feel abrupt.
Does #1 on Artificial Analysis mean it is the best video model overall?
No. It means users are preferring its outputs in blind comparisons on that arena. It does not, by itself, answer questions about access, workflow fit, API readiness, licensing, or operational reliability.
Should creators switch from Seedance or Kling right now?
Not automatically. The better move is to watch HappyHorse-1.0 closely, compare it when access becomes clearer, and keep using proven tools if your pipeline depends on immediate availability and stable integration.
What should teams verify before adopting it?
Teams should verify API availability, standalone access, licensing, documentation, and whether the public “open source soon” claims actually resolve into usable releases. Those questions matter as much as ranking position once a model moves from hype into production.

HappyHorse-1.0 vs Seedance 2.0: Quality or Access?
Apr 07, 2026
What Is HappyHorse-1.0? The Mystery AI Video Model Overtaking Seedance 2.0
Apr 09, 2026
Best Sora Alternative in 2026: Why Dreamface Is the Better Choice
Mar 25, 2026
DreamClaw Agent: The All-in-One AI Automation Engine for DreamFace
Mar 04, 2026
HappyHorse-1.0 vs Seedance 2.0: Quality or Access?
Compare HappyHorse-1.0 and Seedance 2.0 on quality, access, workflow fit, and risk to see which AI video model makes more sense for creators.
By Elizabeth 一 Apr 07, 2026- AI Video
- AI Video Generator
- HappyHorse
What Is HappyHorse-1.0? The Mystery AI Video Model Overtaking Seedance 2.0
Right now, HappyHorse-1.0 is best understood as a mystery AI video model that has rapidly gained attention for its strong text-to-video performance. It is anonymous, it does not yet have the kind of mainstream product presence that other major models have, and it is still surrounded by speculation.
By Elizabeth 一 Apr 07, 2026- AI Video Generator
- HappyHorse
- AI Video
Best Sora Alternative in 2026: Why Dreamface Is the Better Choice
When Sora first appeared, it felt like one of those rare AI moments that genuinely stopped people in their tracks. At the end of 2024, OpenAI’s video product exploded across social media. People were generating cinematic clips, inserting themselves into movie-like scenes, and sharing AI-made videos that looked far beyond what most users thought was possible.
By Elizabeth 一 Apr 07, 2026- Sora 2
- AI Video
- AI Video Generator
- X
- Youtube
- Discord